探索医疗科技的未来:达摩院在多模态大模型领域的创新尝试
当AI走进医院、面对复杂的医学影像和专业任务时,真正的挑战才刚刚开始。
在人工智能飞速发展的今天,多模态大语言模型(MLLMs)已在通用视觉理解领域展现出惊人潜力。然而。当AI走进医院、面对复杂的医学影像和专业任务时,真正的挑战才刚刚开始。
1.知识局限:医学知识覆盖不全,仅靠影像远远不够;
2.幻觉频现:回答看似有理,实则漏洞百出,容易“一本正经地胡说八道”;
3.推理匮乏:面对复杂病情,AI常常缺乏像医生那样的推理能力。
为了解决这些难题,阿里巴巴达摩院团队在医疗领域进行初步尝试,打造了医疗领域的多模态大模型!
数据底子扎实,懂医学也懂“常识”:该模型背后是一套覆盖广泛的高质量数据处理和合成流程,吸收了海量医学文本和通用知识内容,通过自动合成技术,构建了高质量的图文描述、医学问答和推理样本。
像医生一样进阶式学习:模型采用“多阶段训练”策略,从基础医学认知,到复杂病例分析,逐步注入专业知识与临床经验,模型能力层层跃升。经过训练,我们希望其更具备基础的医学逻辑与推理能力,初步展现出处理真实世界医疗任务的潜力。
考试标准严苛,评估体系权威:为确保模型不是“闭门造车”,团队特别开发了MedEvalKit评估体系,涵盖多模态问答、文本问答和医学报告生成等关键任务,对接真实医疗场景,全面衡量模型能力与安全性。
成绩领先,全面超越主流大模型:在多个权威多模态医疗测试中,32B模型以平均高出第二名7.2个百分点的成绩刷新记录,超越GPT-4.1与Claude Sonnet 4等商用领先模型,展现出强大的专业应用潜力。
当前多模态大模型在医疗领域面临的挑战
1. 医学知识覆盖不全,深度不足
过于依赖影像-文本对:许多现有工作主要通过对齐医学影像和相关的文本描述(如放射报告)来学习。这种方式虽然能建立基本的视觉-语言联系,但对于影像之外的广阔医学知识,如药理学、病理生理学、临床指南、公共卫生知识等的覆盖非常有限。
对多模态整合的深度和广度不足:可能过于偏重某一模态(如X光片),对其他重要医学影像模态(如病理、内镜、超声等)的覆盖和理解不足。
2. 数据质量参差不齐,易产生“幻觉”
开源数据噪声大:许多公开的医学多模态数据集来源于科研论文自动抽取或网络抓取,不可避免地含有噪声、不准确信息或冗余内容。
数据合成质量难控:一些工作尝试通过模型蒸馏等方式合成数据,但如果缺乏有效的监督和质量控制,合成数据可能继承甚至放大基础模型的偏见或错误,导致模型更容易产生“幻觉”(即生成不符合事实或无意义的内容)。
缺乏细粒度标注:医学影像的解读需要精确到细节,但很多数据集的标注较为粗糙,难以支撑模型学习细致的病灶特征和微妙的诊断线索。
3. 缺乏针对复杂医疗场景的推理能力
简单问答为主:现有模型在处理简单的图像描述或直接问答(如“图片中是什么器官?”)方面可能表现尚可,但面对需要多步推理、整合多源信息、进行鉴别诊断等复杂医疗场景时,其推理能力往往不足。
“黑箱”特性:许多模型的决策过程不透明,难以解释其诊断或建议的依据,这在对可靠性和可解释性要求极高的医疗领域是严重缺陷。
4. 评测标准不统一,难以横向比较
各自为政的评估:不同研究往往在不同的数据集子集、不同的评估指标上进行评测,导致模型之间的性能难以进行公平、直接的比较。
复现困难:许多模型的代码和数据不完全公开,或者环境配置复杂,使得其他研究者难以复现其结果,阻碍了领域的发展。
为了解决上述问题,我们从数据构造,模型训练以及评测框架三个层面进行探索。
数据构造
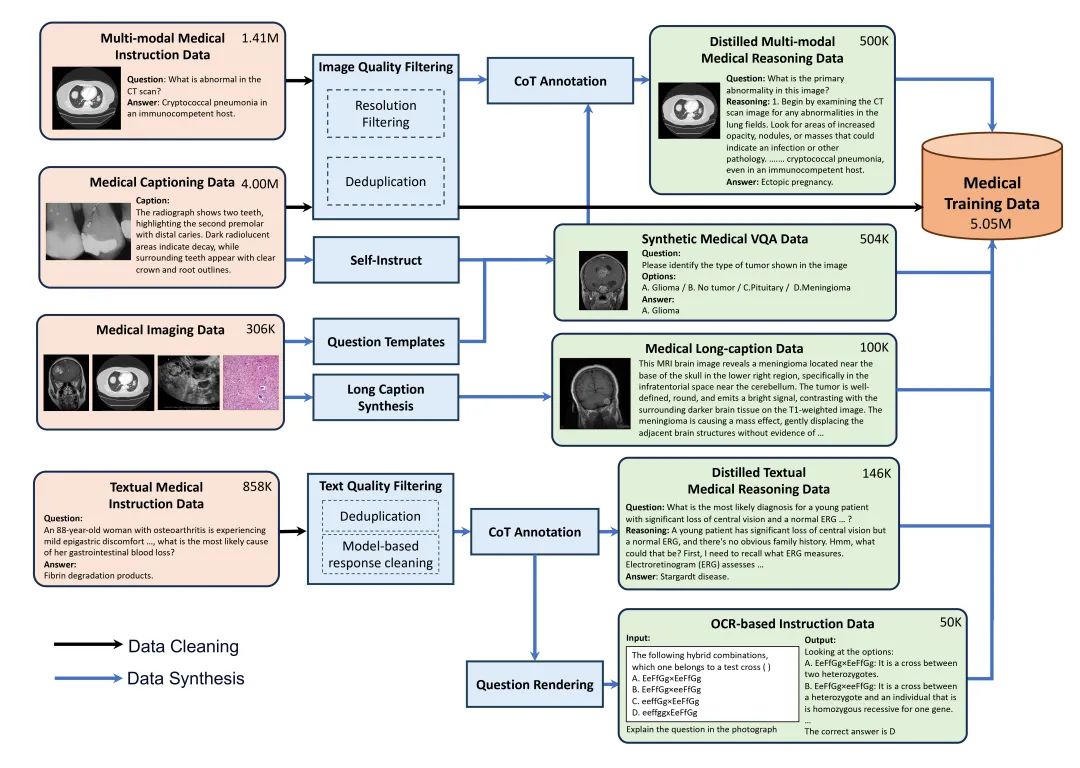
要让AI真正“懂医学”,离不开高质量的数据,但医学领域的数据不仅少,而且复杂、难获取。为此,我们构造了一套全流程的医疗多模态数据收集和合成流程。
1. 高质量的数据合成和增强:面对一些简短、模糊的医学描述,我们用大模型能力“补全细节”,生成更丰富、更专业的图文解释。同时从专业医学教材和题库提取图文信息生成指令数据,提高对嵌入文本的识别能力。此外还合成了大量的医学视觉问答数据,帮助模型回答诊断和医学相关的问题。最后我们还设计了CoT医疗推理数据合成流程,生成医疗的推理思维链路数据,帮助模型更好理解复杂医学问题。
2. 严格质量控制:所有数据经过严格筛选和清洗,比如图像和文本去重、答案准确性检查等,以确保数据的高质量和相关性。
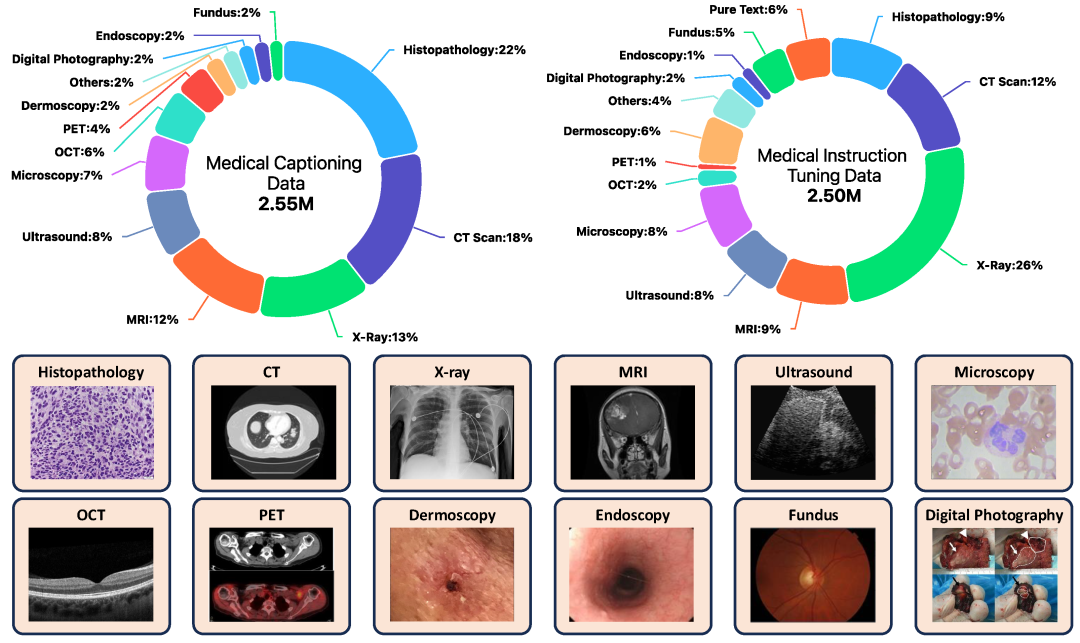
通过以上流程,我们一共得到2.55M条高质量医疗描述数据和2.5M医疗指令数据,同时引入了大量通用域的数据,作为模型训练基础。
模型训练
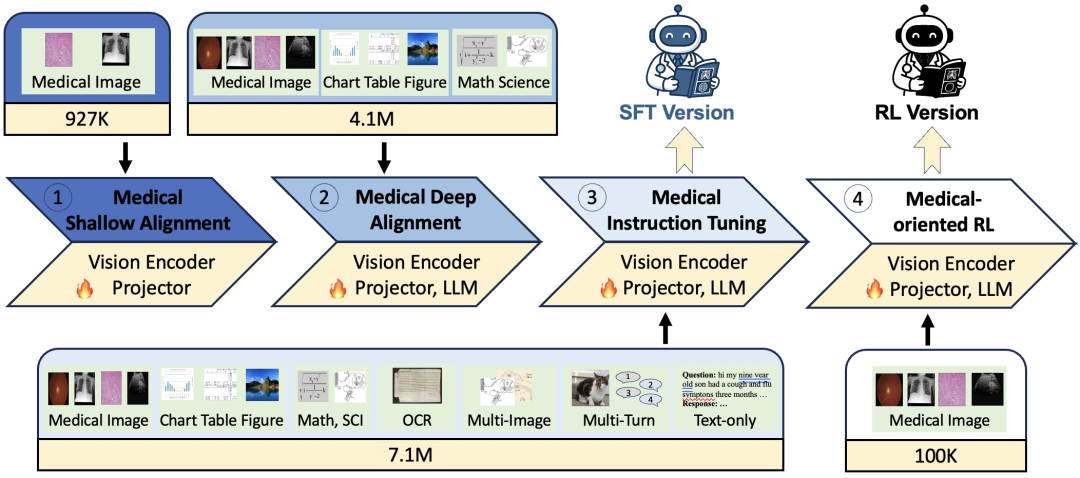
多模态医学大模型基于Qwen2.5-VL(7B和32B的Instruct版本)进行持续训练,为了更好的让模型深入理解多模态医疗知识,我们设计了以下多阶段训练范式:
1. 医疗浅层对齐:我们先让模型对医学影像(如X光、CT、MRI)与对应的医学描述的理解能力。初步建立医学影像特征与语言模型表征空间的连接。通过快速适应医学影像的基本特征,为后续深层融合奠定基础。
2. 医疗深层对齐:我们使用更复杂、更长的图文数据,还加入了通用世界知识数据,进行端到端微调。 让模型能深度融合多模态医学信息,从而有可能处理更细致的医学内容,比如肿瘤特征、病变位置等,朝着“通用医生”进行努力。
3. 医疗指令微调:我们使用大规模、多样化的医疗指令数据(包括VQA、报告生成、OCR、CoT推理等)以及通用的多模态/文本指令数据和医学文本数据进行端到端微调,增强模型的任务泛化能力和复杂场景的应答能力,使其更贴近实际医疗应用。
4. 面向医疗的强化学习 :我们还初步探索了强化学习训练在对医疗多模态任务提升的潜力。我们构建了约10万条的医疗可验证数据集,采用可验证奖励强化学习(RLVR)范式,利用GRPO算法进行训练。期望探索通过奖励信号引导模型生成更准确、更具逻辑性的医疗推理路径。
统一的评测框架 :MedEvalKit
为解决现有医疗MLLMs 评测标准不一、复现困难的问题,我们开发了一个涵盖面广,易于使用,高效评测的医疗评测框架MedEvalKit。
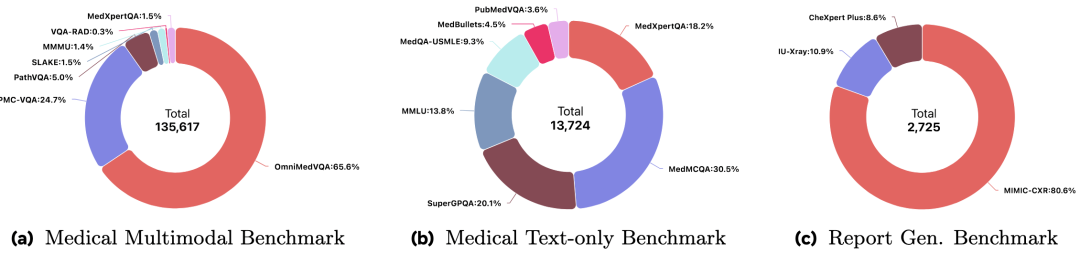
1. MedEvalKit汇集了主流的医疗多模态和文本评测基准,包括:
a. 多模态QA:VQA-RAD, SLAKE, PathVQA, PMC-VQA (v2), OmniMedVQA, MMMU (Health & Medical), MedXpertQA (multimodal)。
b. 文本QA:MMLU (medical subset), PubMedQA, MedMCQA, MedQA-USMLE, MedBullets, MedXpertQA (text), SuperGPQA。
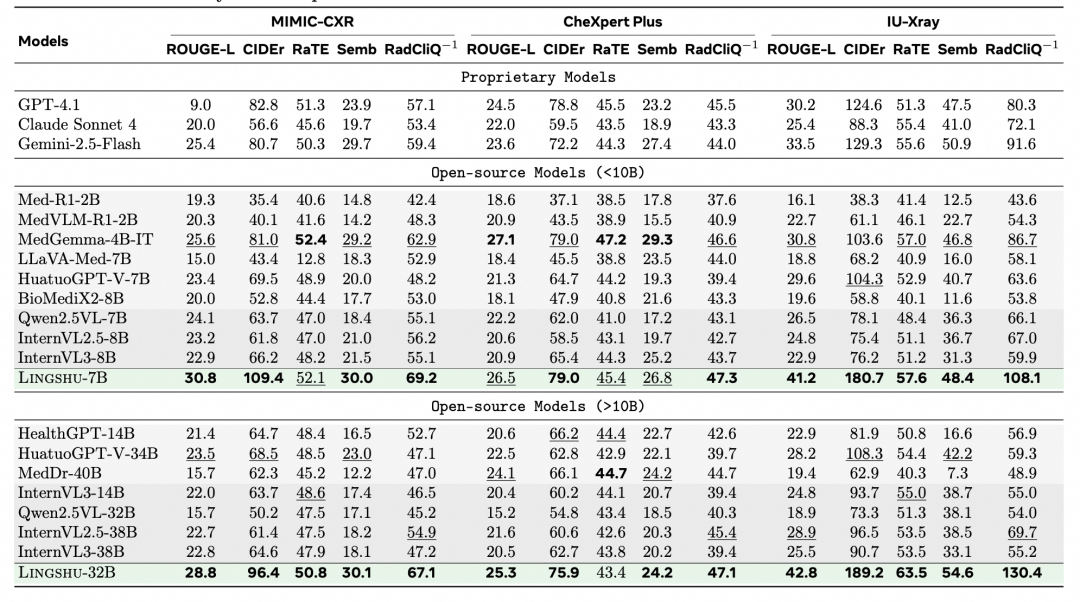
c. 报告生成:MIMIC-CXR, IU-Xray, CheXpert Plus。共计覆盖16个基准数据集,15.2万评估样本和12.1万张不同的医学影像。
2. 标准化流程:统一了数据预处理、模型推理接口和后处理协议,支持一键式评估。
3. 多维度评估:针对不同任务类型采用特定评估指标(如QA任务的准确率,报告生成任务的ROUGE-L, CIDEr, SembScore, RaTEScore, RadCliQ-v1)。并支持“LLM-as-a-Judge”策略辅助评估,兼顾客观与主观评价。
4. 高效与可扩展:支持vLLM进行推理加速;支持多种模型评测;支持多种输出模式评测(如直接输出答案评测,先推理后解析答案进行评测等)。
模型结果
我们使用MedEvalKit上对我们的医疗多模态大模型和当前主流多模态医疗模型进行了全面评估:
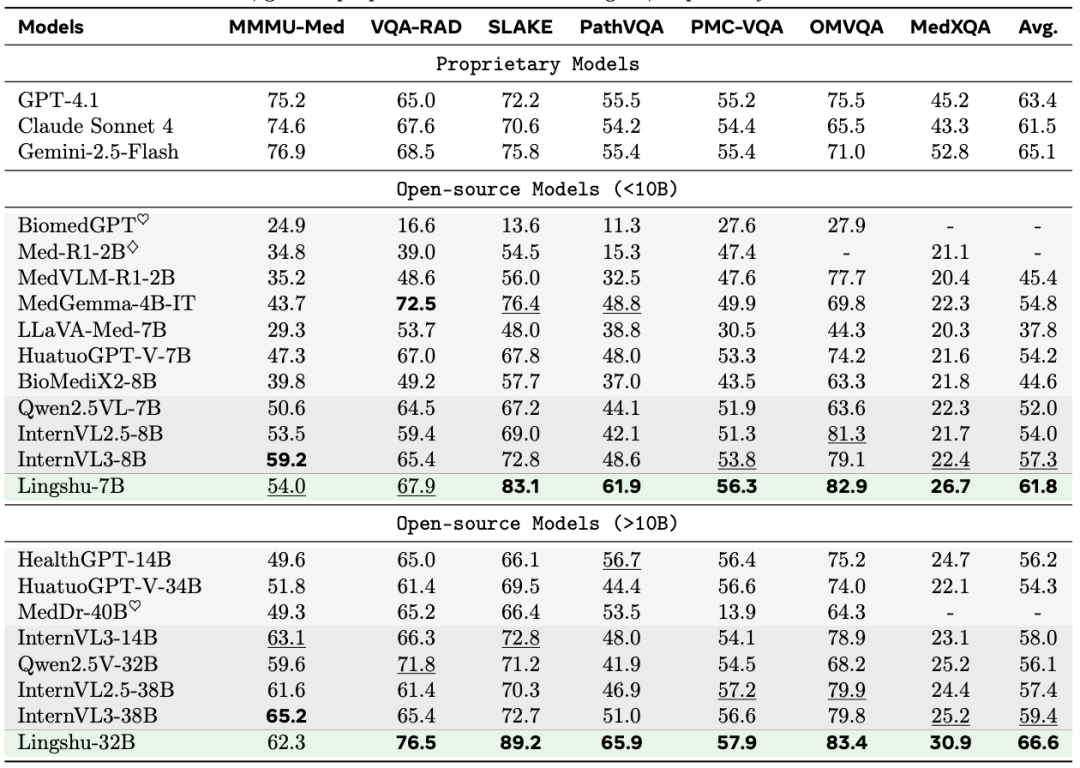
1. 医疗多模态问答测试:
a. 32B模型在所有7个多模态基准测试中取得了平均66.6%的准确率,超越了包括GPT-4.1 (63.4%)、Claude Sonnet 4 (61.5%) 和 Gemini-2.5-Flash (65.1%) 在内的所有专有模型和开源模型,并在VQA-RAD, SLAKE, PathVQA, OmniMedVQA, MedXpertQA-Multimodal 等多个数据集上取得最佳成绩。
b. 7B模型在<10B参数规模的开源模型中表现最佳,平均准确率达到61.8%,显著优于其他同类模型。
2. 在医疗文本基准测试和医学报告生成:我们的模型也表现优异,超越了所有对比的开源模型。
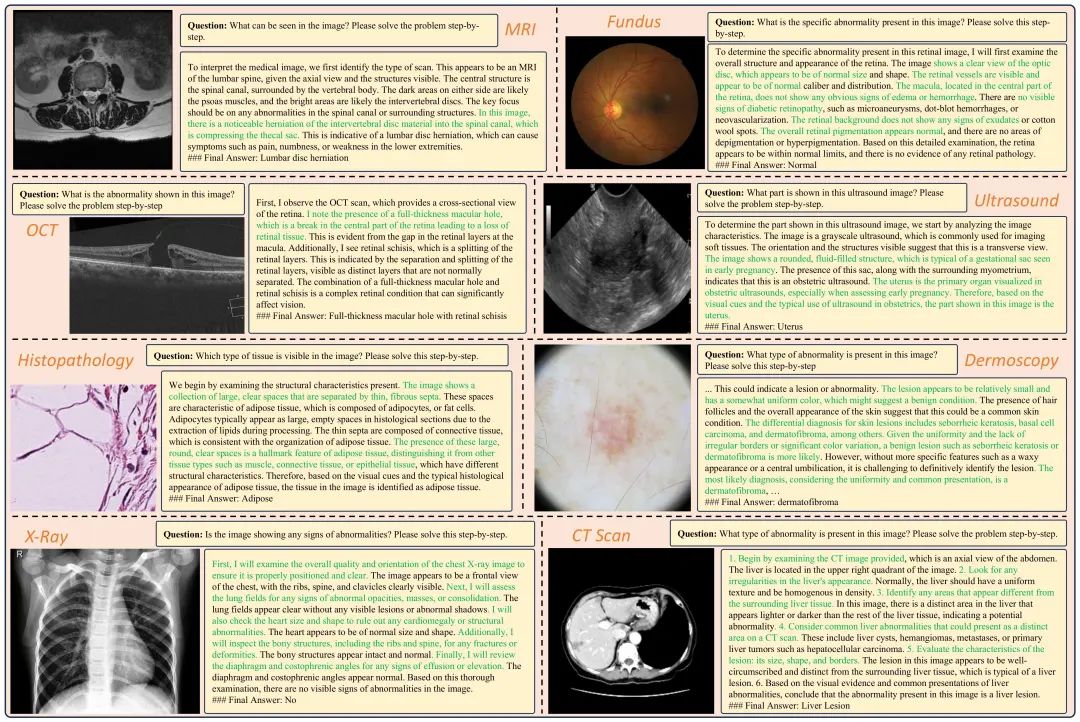
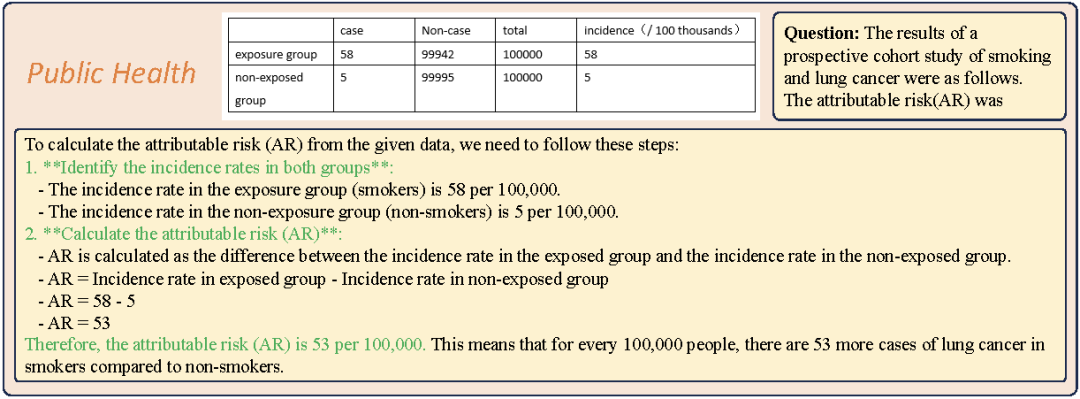
3. 除了标准数据评测外,我们也展示了在医学影像问答、医学诊断、医学知识解释、公共卫生问题分析以及医学报告生成等真实场景中的应用潜力。


未来方向
虽然我们的模型在多个权威多模态医疗测试取得领先,然而在使用过程中仍会出现幻象,无法准确识别病种等问题。因此在推动医疗多模态大模型发展的过程中,我们总结出五个值得关注的核心方向,以突破当前技术瓶颈,提升模型在真实临床中的应用价值:
1. 高质量医疗数据的构建 :当前医学图文数据稀缺且获取成本高,未来需投入更多资源构建多样化、高可信度的数据集,并引入“人在环路”(human-in-the-loop)的自动化评估与优化机制,提升数据质量与产出效率。
2. 更全面的医疗多模态基准:现有医疗基准未能充分反映复杂的真实场景。未来需借鉴HealthBench等框架,打造更具代表性、更实用的医学多模态评估体系,更准确地衡量模型在临床中的表现。
3. 扩展模型能力边界:当前模型对3D影像、超高分辨率病理图(WSI)、组学数据等的支持仍依赖预处理。未来将发展原生支持新模态的能力,使模型更好地理解CT、MRI、病理、基因组等复杂医学信息。
4. 面向医疗场景的训练策略优化:医学领域推理高度依赖临床经验与知识。后续训练需要更加聚焦医疗语境,开发定制化奖励函数&过程监督方法,探索针对医疗MLLMs的强化学习方法。让模型的输出更契合医疗任务需求,满足专业医疗场景下复杂的医疗推理需求。
5. 医疗相关专业评估指标引入:虽然MedEvalKit已初步引入医学任务指标,但当前仍以通用评估标准为主。未来应进一步引入如C-index、临床疗效评分、决策曲线分析等医学专用指标,同时结合专家人工评审,全面提升模型评估的可信度、实用性与安全保障。
本网站上的内容(包括但不限于文字、图片及音视频),除转载外,均为时代在线版权所有,未经书面协议授权,禁止转载、链接、转贴或以其他 方式使用。违反上述声明者,本网将追究其相关法律责任。如其他媒体、网站或个人转载使用,请联系本网站丁先生:news@www.funengjixie.com






